Set up hypercore
Reduce chunk size by up to 98% and speed up queries by converting data between the rowstore and columnstore
Hypercore is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities.
Hypercore dynamically stores data in the most efficient format for its lifecycle:
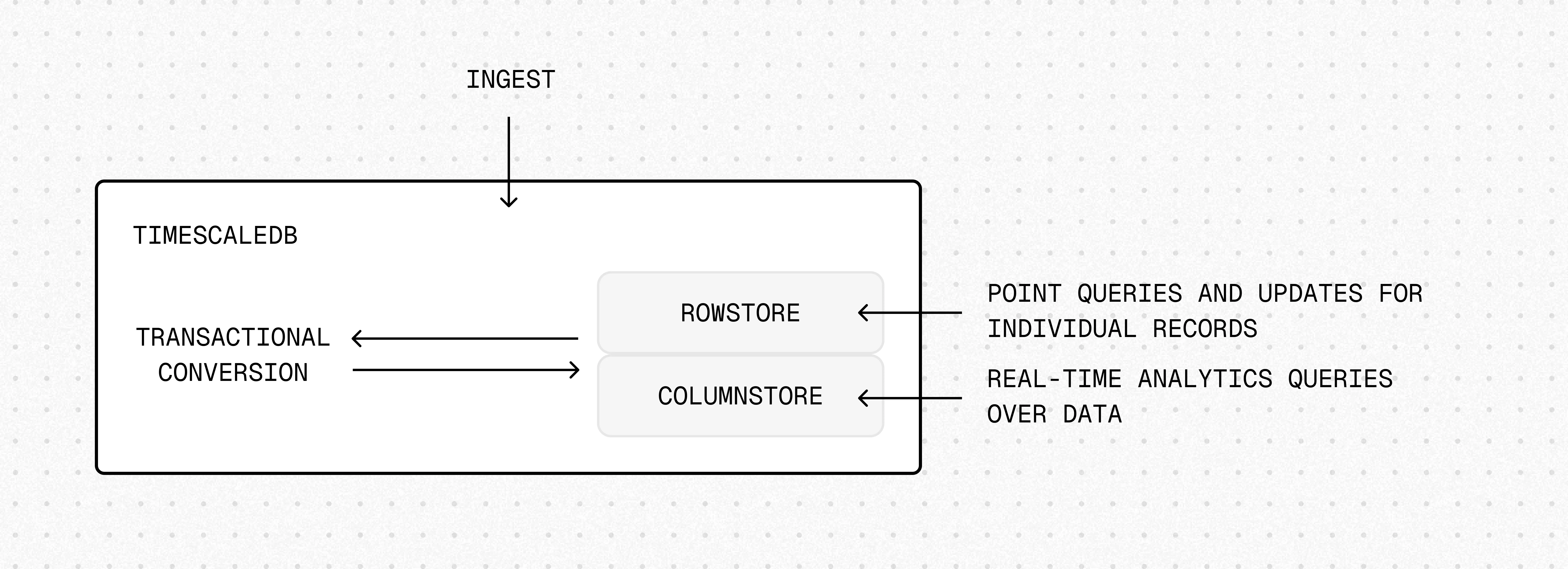
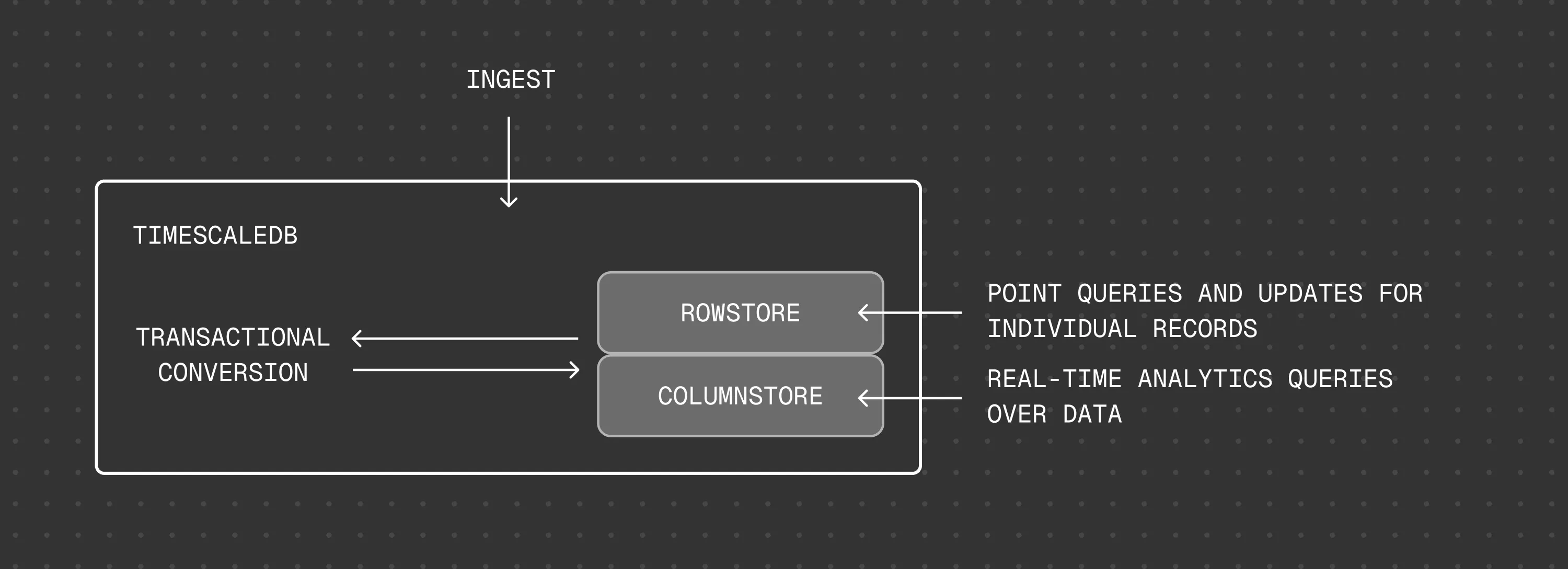
- Row-based storage for recent data: the most recent chunk (and possibly more) is always stored in the rowstore, ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
- Columnar storage for analytical performance: chunks are automatically compressed into the columnstore, optimizing storage efficiency and accelerating analytical queries.
Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a flexible solution for both high-ingest transactional workloads and real-time analytics, within a single database.
When you convert chunks from the rowstore to the columnstore, multiple records are grouped into a single row. The columns of this row hold an array-like structure that stores all the data. For example, data in the following rowstore chunk:
| time | symbol | price | day_volume |
|---|---|---|---|
| 12:00:01 | BTC/USD | 42000.50 | 130 |
| 12:00:01 | ETH/USD | 2200.70 | 205 |
| 12:00:02 | BTC/USD | 42000.12 | 132 |
| 12:00:02 | ETH/USD | 2200.69 | 234 |
| 12:00:03 | BTC/USD | 42000.14 | 130 |
| 12:00:03 | ETH/USD | 2200.70 | 252 |
Is converted and compressed into arrays in a row in the columnstore:
| time | symbol | price | day_volume |
|---|---|---|---|
| [12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03] | [BTC/USD, ETH/USD, BTC/USD, ETH/USD, BTC/USD, ETH/USD] | [42000.50, 2200.70, 42000.12, 2200.69, 42000.14, 2200.70] | [130, 205, 132, 234, 130, 252] |
Because a single row takes up less disk space, you can reduce your chunk size by up to 98%, and can also speed up your queries. This saves on storage costs, and keeps your queries operating at lightning speed.
For an in-depth explanation of how hypertables and hypercore work, see the Data model.
This page shows you how to convert chunks in a hypertable from the rowstore to the columnstore — automatically with a columnstore policy or manually for finer control — and how to get the best compression and query performance from your data.
Prerequisites for this procedure
Convert your data to the columnstore
Section titled “Convert your data to the columnstore”The compression ratio and query performance of data in the columnstore is dependent on the order and structure of your
data. Rows that change over a dimension should be close to each other. With time-series data, you orderby the time
dimension. For example, time:
| time | symbol | price | day_volume |
|---|---|---|---|
| 12:00:01 | BTC/USD | 42000.50 | 130 |
This ensures that records are compressed and accessed in the same order. However, you would always have to access the data using the time dimension, then filter all the rows using other criteria. To make your queries more efficient, you segment your data based on the following:
- The way you want to access it. For example, to rapidly access data about a
single symbol, you
segmentbythesymbolcolumn. This enables you to run much faster analytical queries on data in the columnstore. - The compression rate you want to achieve. The lower the cardinality of the
segmentbycolumn, the better compression results you get.
When TimescaleDB converts a chunk to the columnstore, it automatically creates a different schema for your
data. It also creates and uses custom indexes to incorporate the segmentby and orderby parameters when
you write to and read from the columnstore.
Choose the conversion path that fits your workload:
Convert automatically with a columnstore policy
A columnstore policy runs as a background job and converts eligible chunks to the columnstore on a schedule. This is the best path for most workloads.
- Connect to your Tiger Cloud service
In Tiger Console open an SQL editor. You can also connect to your service using psql.
- Enable the columnstore and add a policy
For efficient queries,
segmentbythe column you filter on most often, andorderbyyour time column. How you enable hypercore depends on what you start from:-
New hypertable
Use
CREATE TABLEto create a hypertable with hypercore enabled by default:CREATE TABLE crypto_ticks ("time" TIMESTAMPTZ,symbol TEXT,price DOUBLE PRECISION,day_volume NUMERIC) WITH (timescaledb.hypertable,timescaledb.segmentby='symbol',timescaledb.orderby='time DESC');When you create a hypertable using CREATE TABLE … WITH …, the default partitioning column is automatically the first column with a timestamp data type. Also, TimescaleDB creates a columnstore policy that automatically converts your data to the columnstore, after an interval equal to the value of the chunk_interval, defined through
afterin the policy. This columnar format enables fast scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space. In the columnstore conversion, hypertable chunks are compressed by up to 98%, and organized for efficient, large-scale queries.You can customize this policy later using alter_job. However, to change
afterorcreated_before, the compression settings, or the hypertable the policy is acting on, you must remove the columnstore policy and add a new one.You can also manually convert chunks in a hypertable to the columnstore.
-
Existing hypertable
Enable the columnstore on a hypertable that already holds data in the rowstore:
ALTER TABLE crypto_ticks SET (timescaledb.enable_columnstore,timescaledb.segmentby = 'symbol',timescaledb.orderby = 'time DESC');These settings apply to chunks that have not yet been converted to the columnstore. For a hypertable that has never used hypercore, that means every chunk. Then add a policy:
CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '7d');The job runs single-threaded, so for a large backlog the initial conversion can take a while to catch up. To convert a backlog faster, convert chunks manually.
-
Existing continuous aggregate
A continuous aggregate is a specialized hypertable. Use
ALTER MATERIALIZED VIEW:ALTER MATERIALIZED VIEW assets_candlestick_daily set (timescaledb.enable_columnstore = true,timescaledb.segmentby = 'symbol');The continuous aggregate must already have a refresh policy before you add a columnstore policy. Then add the policy:
CALL add_columnstore_policy('assets_candlestick_daily', after => INTERVAL '1d');
TimescaleDB is optimized for fast updates on compressed data in the columnstore. To modify data in the columnstore, use standard SQL.
-
- Check the columnstore policy
When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space saved:
SELECTpg_size_pretty(before_compression_total_bytes) as before,pg_size_pretty(after_compression_total_bytes) as afterFROM hypertable_columnstore_stats('crypto_ticks');You see something like:
before after 194 MB 24 MB View the policies that you set or that already exist:
SELECT * FROM timescaledb_information.jobsWHERE proc_name='policy_compression'; - Remove a policy or disable the columnstore
To remove a columnstore policy while keeping existing chunks in the columnstore:
CALL remove_columnstore_policy('crypto_ticks');See remove_columnstore_policy. To disable the columnstore entirely, first convert the chunks back to the rowstore, then:
ALTER TABLE crypto_ticks SET (timescaledb.enable_columnstore = false);
Convert chunks manually
Call convert_to_columnstore on individual chunks when you want finer control than a policy gives you — for example, to convert a large backlog faster than the single-threaded policy job can. The columnstore settings that you set with ALTER TABLE still apply.
- List the chunks to convertSELECT show_chunks('crypto_ticks', older_than => INTERVAL '7d');
- Convert the chunks
Chunks are converted independently, so you can run
convert_to_columnstoreon distinct chunks from multiple sessions in parallel:-- Session 1CALL convert_to_columnstore('_timescaledb_internal._hyper_1_2_chunk');-- Session 2 (concurrent)CALL convert_to_columnstore('_timescaledb_internal._hyper_1_3_chunk');Each call takes an exclusive lock on the chunk it is converting. Different chunks do not block each other, so parallel sessions speed up an initial migration. Match the degree of parallelism to your service’s available CPU and I/O.
Backfill while converting
This applies whether you convert with a policy or manually. Conversion contends on locks with any concurrent write to the same chunk. If you backfill old data while a columnstore policy or a manual convert_to_columnstore call is running, the two operations wait on each other and one can fail or stall. For a clean migration:
- Pause the columnstore policy
Find the
job_id:SELECT job_id FROM timescaledb_information.jobsWHERE proc_name = 'policy_compression' AND hypertable_name = 'crypto_ticks';Then pause the policy:
SELECT alter_job(<JOB_ID>, scheduled => false); - Backfill your data
Run your backfill while the policy is paused, so it does not contend with conversion for locks.
- Convert the affected chunks
Convert the chunks you backfilled into the columnstore. See Convert chunks manually.
- Re-enable the policySELECT alter_job(<JOB_ID>, scheduled => true);
For the full pause-backfill-reconvert workflow, see convert_to_rowstore.
Reference
Section titled “Reference”For integers, timestamps, and other integer-like types, data is compressed using delta encoding, delta-of-delta, simple-8b, and run-length encoding. For columns with few repeated values, XOR-based and dictionary compression is used. For all other types, dictionary compression is used.